A Unified Framework for Piecewise Semantic Reconstruction in Dynamic Scenes via Exploiting Superpixel Relations
Abstract
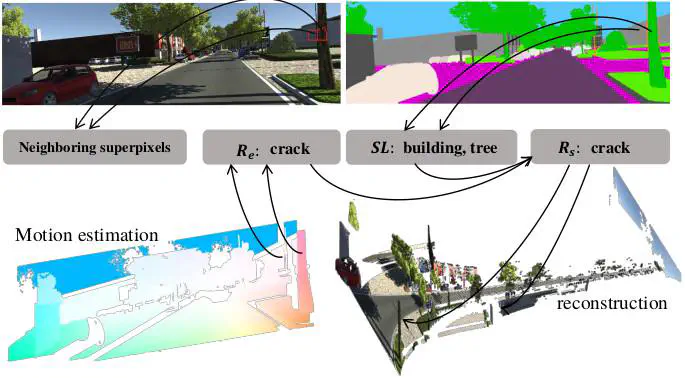
This paper presents a novel framework for dense piecewise semantic reconstruction in dynamic scenes containing complex background and moving objects via exploiting superpixel relations. We utilize two kinds of superpixel relations: motion relations and spatial relations, each having three subcategories: coplanar, hinge, and crack. Spatial relations provide constraints on the spatial locations of neighboring superpixels and thus can be used to reconstruct dynamic scenes. However, spatial relations can not be estimated directly with epipolar geometry due to moving objects in dynamic scenes. We synthesize the results of semantic instance segmentation and motion relations to estimate spatial relations. Given consecutive frames, we mainly develop our method in five main stages: preprocessing, motion estimation, superpixel relation analysis, reconstruction and refinement. Extensive experiments on various datasets demonstrate that our method outperforms competitors in reconstruction quality. Furthermore, our method presents a feasible way to incorporate semantic information in Structure-from-Motion (SFM) based reconstruction pipelines.