Zero and R2D2: A large-scale Chinese cross-modal benchmark and A vision-language framework
Abstract
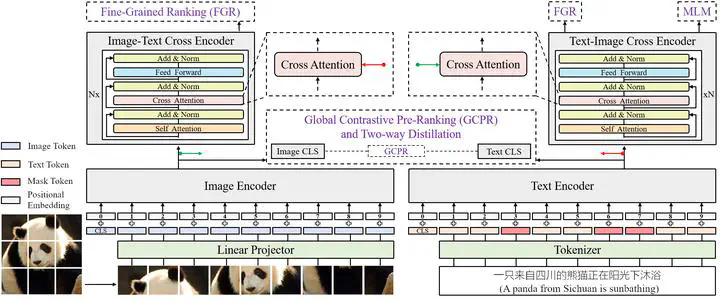
Vision-language pre-training (VLP) on large-scale datasets has shown premier performance on various downstream tasks. In contrast to plenty of available benchmarks with English corpus, large-scale pre-training datasets and downstream datasets with Chinese corpus remain largely unexplored. In this work, we build a large-scale high quality Chinese cross-modal benchmark named ZERO for the research community, which contains the currently largest public pre-training dataset ZERO-Corpus and five human annotated fine-tuning datasets for downstream asks. ZERO-Corpus contains 250 million images paired with 750 million text descriptions, plus two of the five fine-tuning datasets are also currently the largest ones for Chinese cross-modal downstream tasks. Along with the ZERO benchmark, we also develop a VLP framework with pre-Ranking + Ranking mechanism, boosted with target-guided Distillation and feature-guided Distillation (R2D2) for large-scale crossmodal learning. A global contrastive pre-ranking is first introduced to learn the individual representations of images and texts. These primitive representations are then fused in a fine-grained ranking manner via an image-text cross encoder and a text-image cross encoder. The target guided distillation and feature-guided distillation are further proposed to enhance the capability of R2D2. With the ZERO-Corpus and the R2D2 VLP framework, we achieve state-of-the-art performance on twelve downstream datasets from five broad categories of tasks including image-text retrieval, image-text matching, image caption, text-to-image generation, and zero-shot image classification. The datasets, models, and codes are available at https://github.com/yuxie11/R2D2