publications
publications by categories in reversed chronological order. generated by jekyll-scholar.
2026
-
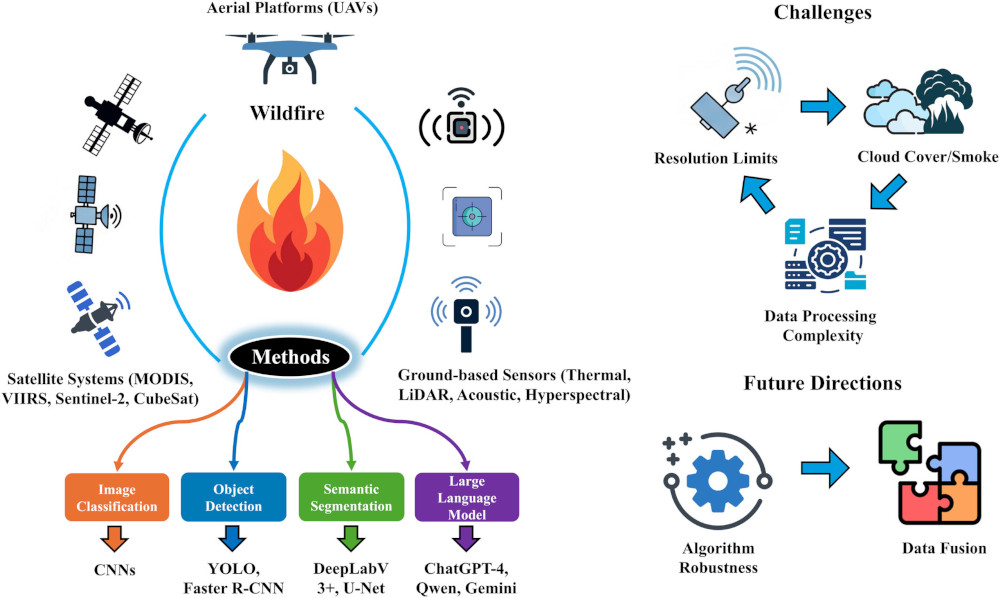 Remote Sensing Techniques Shaping the Future of Wildfire Early DetectionMuneeb Raza, Xu-Cheng Yin, Touqeer Abbas, Israr Ahmad, Rana W. Aslam, Tanveer Muhammad F., and Henrique MorimitsuWIREs Data Mining and Knowledge Discovery, 2026
Remote Sensing Techniques Shaping the Future of Wildfire Early DetectionMuneeb Raza, Xu-Cheng Yin, Touqeer Abbas, Israr Ahmad, Rana W. Aslam, Tanveer Muhammad F., and Henrique MorimitsuWIREs Data Mining and Knowledge Discovery, 2026The global wildfire crisis requires comprehensive early detection strategies to reduce environmental, economic, and societal impacts. This review systematically evaluates remote sensing (RS) technologies employed in early wildfire detection, classifying them into satellite systems, aerial platforms, and ground-based sensors. Subsequently, it critically examines detection methodologies, which include image classification, object detection, semantic segmentation, and emergent approaches utilizing large language models (LLMs). Analysis reveals that deep learning (DL) significantly improves detection accuracy; however, its effectiveness is limited by resolution constraints, especially in the context of detecting smaller fires. As an advanced extension of the DL paradigm, LLMs built upon transformer-based architectures complement conventional DL methods by enabling contextual reasoning over multimodal inputs, thereby bridging the gap between raw visual feature extraction and high-level semantic interpretation. In this regard, LLMs demonstrate considerable potential in synthesizing complex, heterogeneous datasets, thereby enhancing the integration of diverse remote sensing data. Despite these advancements, substantial challenges remain, including limitations in spatial and temporal resolution, environmental interference, and complexities associated with data processing. To mitigate these obstacles, prospective research endeavors should prioritize strengthening algorithmic robustness, refining data fusion methodologies, and establishing real-time monitoring systems. By integrating existing methodologies and outlining key challenges, this study aims to guide future academic inquiry in enhancing wildfire risk mitigation strategies and improving early detection frameworks.
@article{Raza2026RemoteSensingTechniques, title = {Remote Sensing Techniques Shaping the Future of Wildfire Early Detection}, author = {Raza, Muneeb and Yin, Xu-Cheng and Abbas, Touqeer and Ahmad, Israr and Aslam, Rana W. and F., Tanveer Muhammad and Morimitsu, Henrique}, journal = {WIREs Data Mining and Knowledge Discovery}, volume = {16}, number = {3}, year = {2026}, doi = {10.1002/widm.70094}, } -
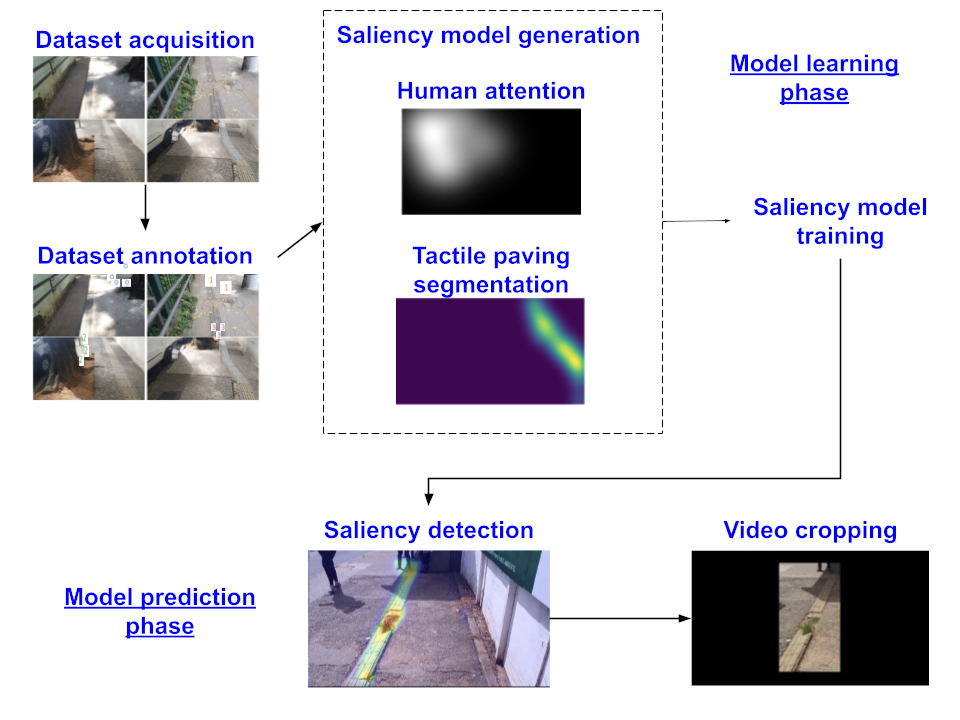 Salience prediction methods for video cropping in sidewalk footageSuayder M. Costa, Rafael J. P. Damaceno, Henrique Morimitsu, and Roberto M. Cesar-Jr.Journal of the Brazilian Computer Society, 2026
Salience prediction methods for video cropping in sidewalk footageSuayder M. Costa, Rafael J. P. Damaceno, Henrique Morimitsu, and Roberto M. Cesar-Jr.Journal of the Brazilian Computer Society, 2026The condition of urban infrastructure is an important aspect in ensuring the safety and well-being of pedestrians. This is especially important around public health facilities, such as sidewalks surrounding hospitals. Computational tools have already demonstrated their potential in this context, including surface material classification and obstacle detection; however, most solutions require labeled data, which is costly and time-consuming. To address this gap, we propose two strategies for salience prediction in videos that reduce the dependence of manual labeling. The first leverages human visual attention, converting user clicks into attention maps. The second employs the SAM2 model to generate labeled video data more efficiently. The outputs of this process are used to train specialized saliency detectors to identify general cracks, surface defects, and key sections of tactile paving, such as directional changes. Also, we apply these saliency models to video cropping in order to highlight the most relevant areas within each frame. This approach enables content-aware video retargeting, supports object-focused attention, and facilitates sidewalk condition analysis by emphasizing defects and potential hazards. This work presents the following contributions: (1) development of a click-based video annotation tool, (2) development of two saliency detection strategies for sidewalks video cropping, (3) training and evaluation of saliency models for sidewalk structure analysis, and (4) successful application of these introduced methods for video cropping. Our experimental results showed that saliency models were able to highlight relevant information in urban environments, achieving an AUC of 0.582 in the best case for human-based attention and 0.914 for tactile-based attention, thereby enhancing assistive technologies for visually impaired individuals.
@article{Costa2026SaliencePredictionMethods, title = {Salience prediction methods for video cropping in sidewalk footage}, author = {Costa, Suayder M. and Damaceno, Rafael J. P. and Morimitsu, Henrique and Cesar-Jr., Roberto M.}, journal = {Journal of the Brazilian Computer Society}, volume = {32}, number = {1}, pages = {649--662}, year = {2026}, doi = {10.5753/jbcs.2026.5895}, }
2025
-
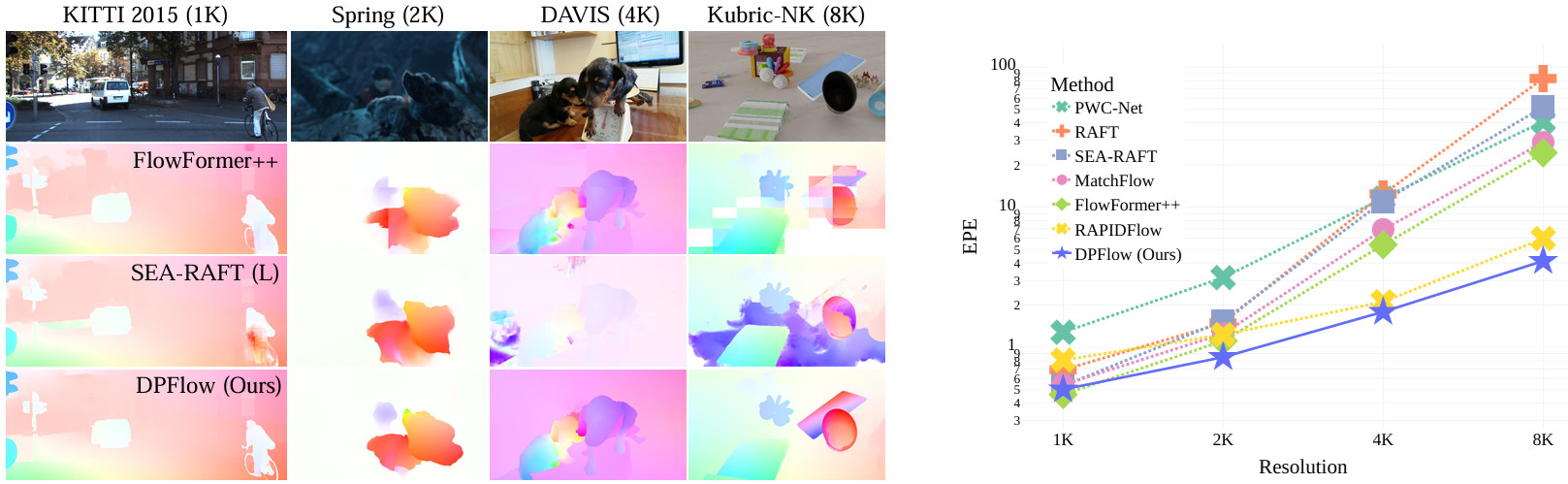 DPFlow: Adaptive Optical Flow Estimation with a Dual-Pyramid FrameworkIn IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025
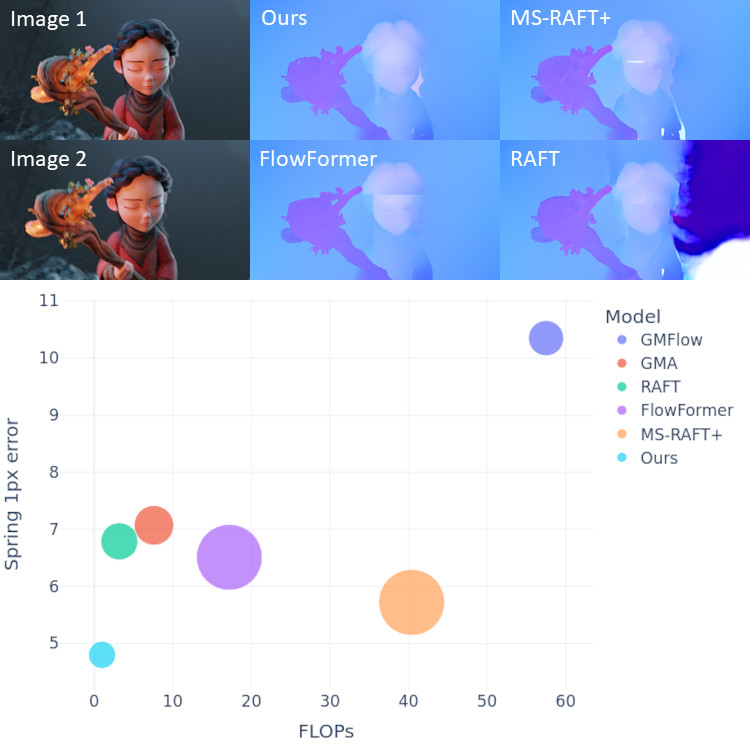
DPFlow: Adaptive Optical Flow Estimation with a Dual-Pyramid FrameworkIn IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025Optical flow estimation is essential for video processing tasks, such as restoration and action recognition. The quality of videos is constantly increasing, with current standards reaching 8K resolution. However, optical flow methods are usually designed for low resolution and do not generalize to large inputs due to their rigid architectures. They adopt downscaling or input tiling to reduce the input size, causing a loss of details and global information. There is also a lack of optical flow benchmarks to judge the actual performance of existing methods on high-resolution samples. Previous works only conducted qualitative high-resolution evaluations on hand-picked samples. This paper fills this gap in optical flow estimation in two ways. We propose DPFlow, an adaptive optical flow architecture capable of generalizing up to 8K resolution inputs while trained with only low-resolution samples. We also introduce Kubric-NK, a new benchmark for evaluating optical flow methods with input resolutions ranging from 1K to 8K. Our high-resolution evaluation pushes the boundaries of existing methods and reveals new insights about their generalization capabilities. Extensive experimental results show that DPFlow achieves state-of-the-art results on the MPI-Sintel, KITTI 2015, Spring, and other high-resolution benchmarks.
@inproceedings{Morimitsu2025DPFlowAdaptiveOptical, author = {Morimitsu, Henrique and Zhu, Xiaobin and Cesar-Jr., Roberto M. and Ji, Xiangyang and Yin, Xu-Cheng}, booktitle = {IEEE/CVF Conference on Computer Vision and Pattern Recognition}, title = {{DPFlow}: Adaptive Optical Flow Estimation with a Dual-Pyramid Framework}, year = {2025}, doi = {https://doi.org/10.1109/CVPR52734.2025.01659}, }
2024
-
 Tactile Path Guidance via Weakly Supervised Visual AttentionSuayder M. Costa, Rafael J. P. Damaceno, Henrique Morimitsu, and Roberto M. Cesar-Jr.In The 4th Annual Workshop on The Future of Urban Accessibility, 2024
Tactile Path Guidance via Weakly Supervised Visual AttentionSuayder M. Costa, Rafael J. P. Damaceno, Henrique Morimitsu, and Roberto M. Cesar-Jr.In The 4th Annual Workshop on The Future of Urban Accessibility, 2024Tactile paving is a structure available on sidewalks that supports visually impaired people in walking independently. Maintaining this and other structures in the urban environment is essential for pedestrians’ safety and well-being. Computational solutions for their assessment, an essential part of urban infrastructure maintainability, require the availability of specific data, which is costly and time-consuming to obtain. In this context, this work proposes using the SAM2 segmentation model as a basis to enhance saliency detection models. These saliency models can then detect important urban features more accurately and with lower costs, making them ideal for deploying on mobile devices. This paper illustrates how this approach can improve the identification of tactile paving to aid the mobility of visually impaired users while also collecting summarized data about the conditions of these structures.
@inproceedings{Costa2024TactilePathGuidance, author = {Costa, Suayder M. and Damaceno, Rafael J. P. and Morimitsu, Henrique and Cesar-Jr., Roberto M.}, booktitle = {The 4th Annual Workshop on The Future of Urban Accessibility}, title = {Tactile Path Guidance via Weakly Supervised Visual Attention}, year = {2024}, } -
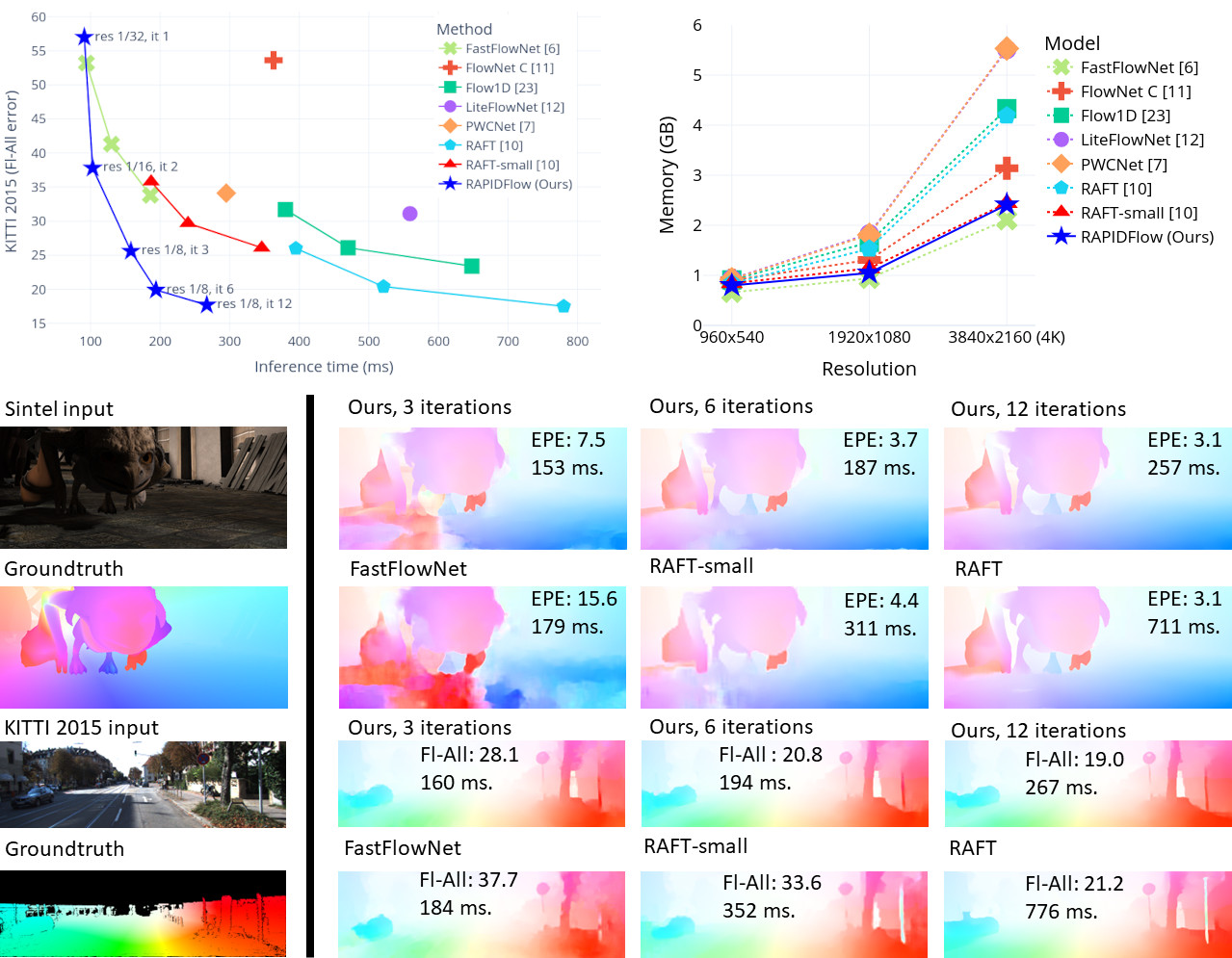 RAPIDFlow: Recurrent Adaptable Pyramids with Iterative Decoding for Efficient Optical Flow EstimationIn International Conference on Robotics and Automation, 2024
RAPIDFlow: Recurrent Adaptable Pyramids with Iterative Decoding for Efficient Optical Flow EstimationIn International Conference on Robotics and Automation, 2024Extracting motion information from videos with optical flow estimation is vital in multiple practical robot applications. Current optical flow approaches show remarkable accuracy, but top-performing methods have high computational costs and are unsuitable for embedded devices. Although some previous works have focused on developing low-cost optical flow strategies, their estimation quality has a noticeable gap with more robust methods. In this paper, we develop a novel method to efficiently estimate high-quality optical flow in embedded devices. Our proposed RAPIDFlow model combines efficient NeXt1D convolution blocks with a fully recurrent structure based on feature pyramids to decrease computational costs without significantly impacting estimation accuracy. The adaptable recurrent encoder produces multi-scale features with a single shared block, which allows us to adjust the pyramid length at inference time and make it more robust to changes in input size. Also, it enables our model to offer multiple tradeoffs between accuracy and speed to suit different applications. Experiments using a Jetson Orin NX embedded system on the MPI-Sintel and KITTI public benchmarks show that RAPIDFlow outperforms previous approaches by significant margins at faster speeds.
@inproceedings{Morimitsu2024RAPIDFlowRecurrentAdaptable, author = {Morimitsu, Henrique and Zhu, Xiaobin and Cesar-Jr., Roberto M. and Ji, Xiangyang and Yin, Xu-Cheng}, booktitle = {International Conference on Robotics and Automation}, title = {{RAPIDFlow}: {Recurrent Adaptable Pyramids with Iterative Decoding} for Efficient Optical Flow Estimation}, year = {2024}, doi = {10.1109/ICRA57147.2024.10610277}, } -
 Recurrent Partial Kernel Network for Efficient Optical Flow EstimationIn AAAI Conference on Artificial Intelligence, 2024
Recurrent Partial Kernel Network for Efficient Optical Flow EstimationIn AAAI Conference on Artificial Intelligence, 2024Optical flow estimation is a challenging task consisting of predicting per-pixel motion vectors between images. Recent methods have employed larger and more complex models to improve the estimation accuracy. However, this impacts the widespread adoption of optical flow methods and makes it harder to train more general models since the optical flow data is hard to obtain. This paper proposes a small and efficient model for optical flow estimation. We design a new spatial recurrent encoder that extracts discriminative features at a significantly reduced size. Unlike standard recurrent units, we utilize Partial Kernel Convolution (PKConv) layers to produce variable multi-scale features with a single shared block. We also design efficient Separable Large Kernels (SLK) to capture large context information with low computational cost. Experiments on public benchmarks show that we achieve state-of-the-art generalization performance while requiring significantly fewer parameters and memory than competing methods. Our model ranks first in the Spring benchmark without finetuning, improving the results by over 10% while requiring an order of magnitude fewer FLOPs and over four times less memory than the following published method without finetuning.
@inproceedings{Morimitsu2024RecurrentPartialKernel, author = {Morimitsu, Henrique and Zhu, Xiaobin and Ji, Xiangyang and Yin, Xu-Cheng}, booktitle = {AAAI Conference on Artificial Intelligence}, title = {Recurrent Partial Kernel Network for Efficient Optical Flow Estimation}, year = {2024}, doi = {10.1609/aaai.v38i5.28224}, }
2023
-
 CCMB: A Large-scale Chinese Cross-modal BenchmarkChunyu Xie, Heng Cai, Jincheng Li, Fanjing Kong, Xiaoyu Wu, Jianfei Song, Henrique Morimitsu, Lin Yao, Dexin Wang, Xiangzheng Zhang, and 4 more authorsIn ACM International Conference on Multimedia, Oct 2023
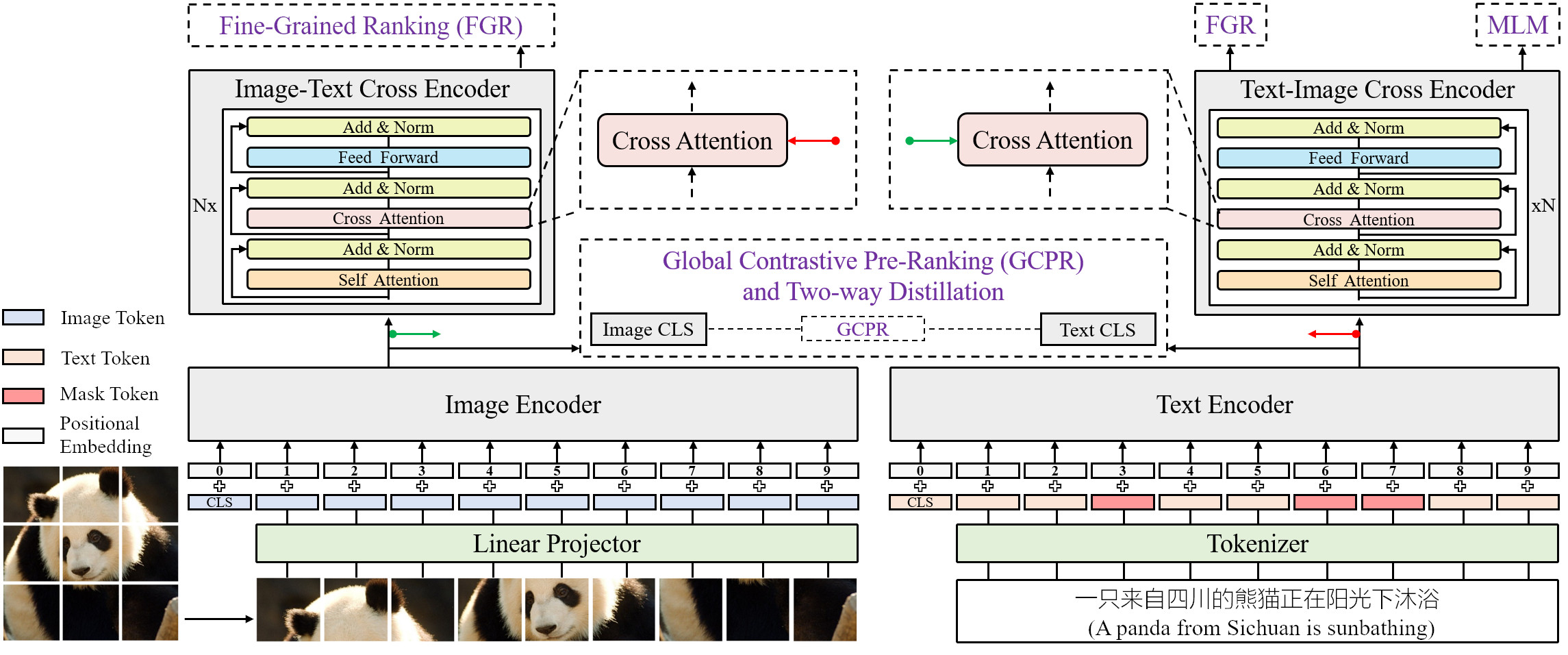
CCMB: A Large-scale Chinese Cross-modal BenchmarkChunyu Xie, Heng Cai, Jincheng Li, Fanjing Kong, Xiaoyu Wu, Jianfei Song, Henrique Morimitsu, Lin Yao, Dexin Wang, Xiangzheng Zhang, and 4 more authorsIn ACM International Conference on Multimedia, Oct 2023Vision-language pre-training (VLP) on large-scale datasets has shown premier performance on various downstream tasks. In contrast to plenty of available benchmarks with English corpus, large-scale pre-training datasets and downstream datasets with Chinese corpus remain largely unexplored. In this work, we build a large-scale high-quality Chinese Cross-Modal Benchmark named CCMB for the research community, which contains the currently largest public pre-training dataset CCMB-Corpus and five human-annotated fine-tuning datasets for downstream tasks. CCMB-Corpus contains 250 million images paired with 750 million text descriptions, plus two of the five fine-tuning datasets are also currently the largest ones for Chinese cross-modal downstream tasks. Along with the CCMB, we also develop a VLP framework named PANDA, providing a strong baseline for Chinese cross-modal learning. With the CCMB-Corpus and the PANDA VLP framework, we achieve state-of-the-art performance on twelve downstream datasets from five broad categories of tasks including image-text retrieval, image-text matching, image caption, text-to-image generation, and zero-shot image classification.
@inproceedings{chunyu2023ccmb, author = {Xie, Chunyu and Cai, Heng and Li, Jincheng and Kong, Fanjing and Wu, Xiaoyu and Song, Jianfei and Morimitsu, Henrique and Yao, Lin and Wang, Dexin and Zhang, Xiangzheng and Leng, Dawei and Zhang, Baochang and Ji, Xiangyang and Deng, Yafeng}, title = {CCMB: A Large-scale Chinese Cross-modal Benchmark}, booktitle = {ACM International Conference on Multimedia}, month = oct, year = {2023}, doi = {10.1145/3581783.3611877}, }
2020
-
 A Unified Framework for Piecewise Semantic Reconstruction in Dynamic Scenes via Exploiting Superpixel RelationsYan Di, Henrique Morimitsu, Zhiqiang Lou, and Xiangyang JiIn International Conference on Robotics and Automation, Jun 2020
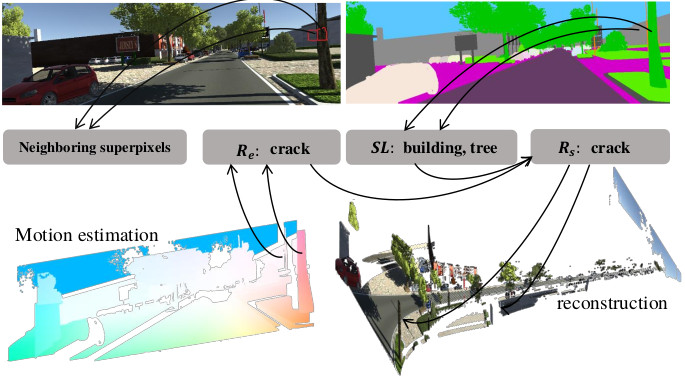
A Unified Framework for Piecewise Semantic Reconstruction in Dynamic Scenes via Exploiting Superpixel RelationsYan Di, Henrique Morimitsu, Zhiqiang Lou, and Xiangyang JiIn International Conference on Robotics and Automation, Jun 2020This paper presents a novel framework for dense piecewise semantic reconstruction in dynamic scenes containing complex background and moving objects via exploiting superpixel relations. We utilize two kinds of superpixel relations: motion relations and spatial relations, each having three subcategories: coplanar, hinge, and crack. Spatial relations provide constraints on the spatial locations of neighboring superpixels and thus can be used to reconstruct dynamic scenes. However, spatial relations can not be estimated directly with epipolar geometry due to moving objects in dynamic scenes. We synthesize the results of semantic instance segmentation and motion relations to estimate spatial relations. Given consecutive frames, we mainly develop our method in five main stages: preprocessing, motion estimation, superpixel relation analysis, reconstruction and refinement. Extensive experiments on various datasets demonstrate that our method outperforms competitors in reconstruction quality. Furthermore, our method presents a feasible way to incorporate semantic information in Structure-from-Motion (SFM) based reconstruction pipelines.
@inproceedings{di2020unified, author = {Di, Yan and Morimitsu, Henrique and Lou, Zhiqiang and Ji, Xiangyang}, title = {A Unified Framework for Piecewise Semantic Reconstruction in Dynamic Scenes via Exploiting Superpixel Relations}, booktitle = {International Conference on Robotics and Automation}, month = jun, year = {2020}, doi = {10.1109/ICRA40945.2020.9197240}, }
2019
-
 Monocular Piecewise Depth Estimation in Dynamic Scenes by Exploiting Superpixel RelationsYan Di, Henrique Morimitsu, Shan Gao, and Xiangyang JiIn International Conference on Computer Vision, Oct 2019
Monocular Piecewise Depth Estimation in Dynamic Scenes by Exploiting Superpixel RelationsYan Di, Henrique Morimitsu, Shan Gao, and Xiangyang JiIn International Conference on Computer Vision, Oct 2019In this paper, we propose a novel and specially designed method for piecewise dense monocular depth estimation in dynamic scenes. We utilize spatial relations between neighboring superpixels to solve the inherent relative scale ambiguity (RSA) problem and smooth the depth map. However, directly estimating spatial relations is an ill-posed problem. Our core idea is to predict spatial relations based on the corresponding motion relations. Given two or more consecutive frames, we first compute semi-dense (CPM) or dense (optical flow) point matches between temporally neighboring images. Then we develop our method in four main stages superpixel relations analysis, motion selection, reconstruction, and refinement. The final refinement process helps to improve the quality of the reconstruction at pixel level. Our method does not require per-object segmentation, template priors or training sets, which ensures flexibility in various applications. Extensive experiments on both synthetic and real datasets demonstrate that our method robustly handles different dynamic situations and presents competitive results to the state-of-the-art methods while running much faster than them.
@inproceedings{di2019monocular, author = {Di, Yan and Morimitsu, Henrique and Gao, Shan and Ji, Xiangyang}, title = {Monocular Piecewise Depth Estimation in Dynamic Scenes by Exploiting Superpixel Relations}, booktitle = {International Conference on Computer Vision}, month = oct, year = {2019}, doi = {10.1109/ICCV.2019.00446}, }
2018
-
 Multiple Context Features in Siamese Networks for Visual Object TrackingHenrique MorimitsuIn ECCV workshops - VOT, 2018
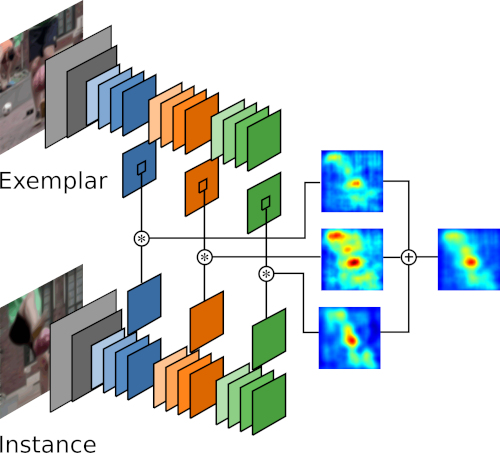
Multiple Context Features in Siamese Networks for Visual Object TrackingHenrique MorimitsuIn ECCV workshops - VOT, 2018Siamese networks have been successfully utilized to learn a robust matching function between pairs of images. Visual object tracking methods based on siamese networks have been gaining popularity recently due to their robustness and speed. However, existing siamese approaches are still unable to perform on par with the most accurate trackers. In this paper, we propose to extend the SiamFC tracker to extract features at multiple context and semantic levels from very deep networks. We show that our approach effectively extracts complementary features for siamese matching from different layers, which provides a significant performance boost when fused. Experimental results on VOT and OTB datasets show that our multi-context tracker is comparable to the most accurate methods, while still being faster than most of them. In particular, we outperform several other state-of-the-art siamese methods.
@inproceedings{morimitsu2018multiple, author = {Morimitsu, Henrique}, title = {Multiple Context Features in Siamese Networks for Visual Object Tracking}, booktitle = {ECCV workshops - VOT}, year = {2018}, doi = {10.1007/978-3-030-11009-3_6}, }
2017
-
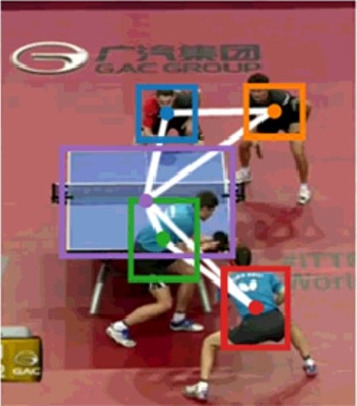 Exploring structure for long-term tracking of multiple objects in sports videosHenrique Morimitsu, Isabelle Bloch, and Roberto M. Cesar-Jr.Computer Vision and Image Understanding, 2017
Exploring structure for long-term tracking of multiple objects in sports videosHenrique Morimitsu, Isabelle Bloch, and Roberto M. Cesar-Jr.Computer Vision and Image Understanding, 2017In this paper, we propose a novel approach for exploiting structural relations to track multiple objects that may undergo long-term occlusion and abrupt motion. We use a model-free approach that relies only on annotations given in the first frame of the video to track all the objects online, i.e. without knowledge from future frames. We initialize a probabilistic Attributed Relational Graph (ARG) from the first frame, which is incrementally updated along the video. Instead of using the structural information only to evaluate the scene, the proposed approach considers it to generate new tracking hypotheses. In this way, our method is capable of generating relevant object candidates that are used to improve or recover the track of lost objects. The proposed method is evaluated on several videos of table tennis, volleyball, and on the ACASVA dataset. The results show that our approach is very robust, flexible and able to outperform other state-of-the-art methods in sports videos that present structural patterns.
@article{morimitsu2017exploring, author = {Morimitsu, Henrique and Bloch, Isabelle and Cesar-Jr., Roberto M.}, title = {Exploring structure for long-term tracking of multiple objects in sports videos}, journal = {Computer Vision and Image Understanding}, year = {2017}, volume = {159}, pages = {89--104}, doi = {10.1016/j.cviu.2016.12.003}, } -
 Keygraphs: Structured Features for Object Detection and ApplicationsMarcelo Hashimoto, Henrique Morimitsu, Roberto Hirata-Jr., and Roberto M. Cesar-Jr.In Pattern Recognition and Big Data, 2017
Keygraphs: Structured Features for Object Detection and ApplicationsMarcelo Hashimoto, Henrique Morimitsu, Roberto Hirata-Jr., and Roberto M. Cesar-Jr.In Pattern Recognition and Big Data, 2017Object detection is one of the most important problems in computer vision and it is the base for many others, such as navigation, stereo matching and augmented reality. One of the most popular and powerful choices for performing object detection is using keypoint correspondence approaches. Several keypoint detectors and descriptors has already been proposed but they often extract information from the neighborhood of each point individually, without considering the structure and relationship between them. Exploring structural pattern recognition techniques is a powerful way to fill this gap. In this chapter the concept of keygraphs is explored for extracting structural features from regular keypoints. Keygraphs provide more flexibility to the description process and are more robust than traditional keypoint descriptors, such as SIFT and SURF, because they rely on structural information. The results observed in different tests show that this simplicity significantly improves the time performance, while also keeping them highly discriminative. The effectivity of keygraphs is validated by using them to detect objects in real-time applications on a mobile phone.
@inproceedings{hashimoto2017keygraphs, author = {Hashimoto, Marcelo and Morimitsu, Henrique and Hirata-Jr., Roberto and Cesar-Jr., Roberto M.}, title = {Keygraphs: Structured Features for Object Detection and Applications}, booktitle = {Pattern Recognition and Big Data}, publisher = {World Scientific}, year = {2017}, editor = {Pal, Amita and Pal, Sankar K.}, }
2015
-
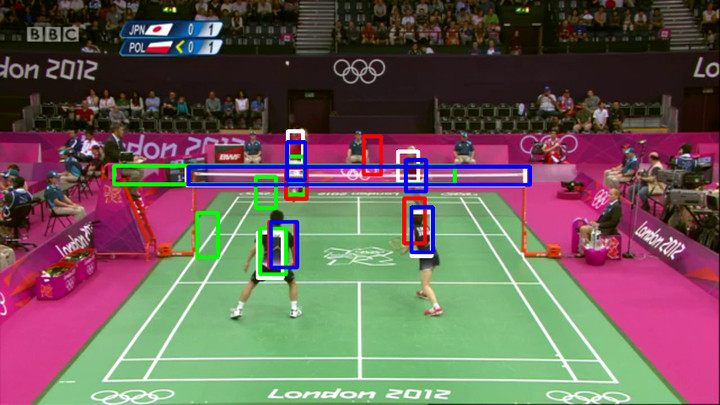 Attributed Graphs for Tracking Multiple Objects in Structured Sports VideosHenrique Morimitsu, Roberto M. Cesar-Jr., and Isabelle BlochIn ICCV Workshops - CVSports, 2015
Attributed Graphs for Tracking Multiple Objects in Structured Sports VideosHenrique Morimitsu, Roberto M. Cesar-Jr., and Isabelle BlochIn ICCV Workshops - CVSports, 2015In this paper we propose a novel approach for tracking multiple object in structured sports videos using graphs. The objects are tracked by combining particle filter and frame description with Attributed Relational Graphs. We start by learning a probabilistic structural model graph from annotated images and then use it to evaluate and correct the current tracking state. Different from previous studies, our approach is also capable of using the learned model to generate new hypotheses of where the object is likely to be found after situations of occlusion or abrupt motion. We test the proposed method on two datasets: videos of table tennis matches extracted from YouTube and badminton matches from the ACASVA dataset. We show that all the players are successfully tracked even after they occlude each other or when there is a camera cut.
@inproceedings{morimitsu2015attributed, title = {Attributed Graphs for Tracking Multiple Objects in Structured Sports Videos}, author = {Morimitsu, Henrique and Cesar-Jr., Roberto M. and Bloch, Isabelle}, booktitle = {ICCV Workshops - CVSports}, pages = {34--42}, year = {2015}, doi = {10.1109/ICCVW.2015.102}, }
2014
-
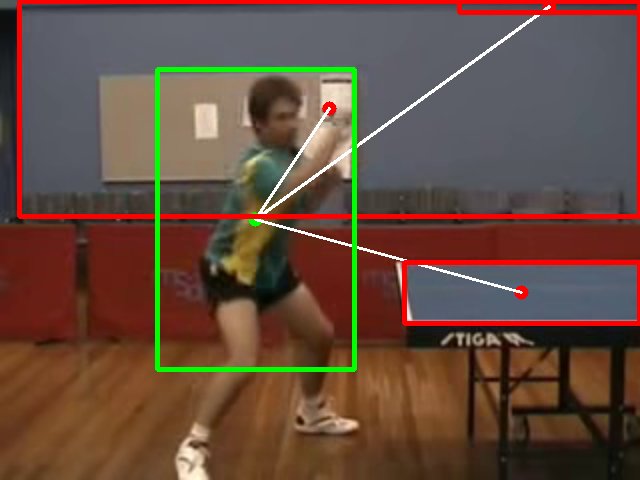 A Spatio-temporal Approach for Multiple Object Detection in Videos Using Graphs and Probability MapsHenrique Morimitsu, Roberto M. Cesar-Jr., and Isabelle BlochIn Image Analysis and Recognition, 2014
A Spatio-temporal Approach for Multiple Object Detection in Videos Using Graphs and Probability MapsHenrique Morimitsu, Roberto M. Cesar-Jr., and Isabelle BlochIn Image Analysis and Recognition, 2014This paper presents a novel framework for object detection in videos that considers both structural and temporal information. Detection is performed by first applying low-level feature extraction techniques in each frame of the video. Then, additional robustness is obtained by considering the temporal stability of videos, using particle filters and probability maps, which encode information about the expected location of each object. Lastly, structural information of the scene is described using graphs, which allows us to further improve the results. As a practical application, we evaluate our approach on table tennis sport videos databases: the UCF101 table tennis shots and an in-house one. The observed results indicate that the proposed approach is robust, showing a high hit rate on the two databases.
@incollection{morimitsu2014spatio, title = {A Spatio-temporal Approach for Multiple Object Detection in Videos Using Graphs and Probability Maps}, author = {Morimitsu, Henrique and Cesar-Jr., Roberto M. and Bloch, Isabelle}, booktitle = {Image Analysis and Recognition}, pages = {421--428}, year = {2014}, doi = {10.1007/978-3-319-11755-3_47} } -
 A graph-based approach for object detection and action recognition in videosHenrique Morimitsu, Roberto M. Cesar-Jr., and Isabelle BlochIn FEAST Workshop of International Conference on Pattern Recognition, 2014
A graph-based approach for object detection and action recognition in videosHenrique Morimitsu, Roberto M. Cesar-Jr., and Isabelle BlochIn FEAST Workshop of International Conference on Pattern Recognition, 2014Recently, the field of action and activity recognition in videos has been receiving a lot of attention. However, in order to be able to classify the actions in the scene, it is necessary to first detect the actors or objects involved. In fact, as already pointed out by former studies, there is a direct relation between the quality of the detection and the performance of action recognition methods. In this work we propose a 3-layer framework that incorporates: low-level feature extraction, graph description and action recognition in videos. This framework will be used to perform action recognition and also improve the overall detection of the objects involved.
@inproceedings{morimitsu2014graph, title = {A graph-based approach for object detection and action recognition in videos}, author = {Morimitsu, Henrique and Cesar-Jr., Roberto M. and Bloch, Isabelle}, booktitle = {FEAST Workshop of International Conference on Pattern Recognition}, year = {2014}, }
2011
-
 Wi-fi and Keygraphs for Localization with Cell PhoneHenrique Morimitsu, Rodrigo B. Pimentel, Marcelo Hashimoto, Roberto M. Cesar-Jr., and Roberto Hirata-Jr.In IEEE International Conference on Computer Vision Workshops, 2011
Wi-fi and Keygraphs for Localization with Cell PhoneHenrique Morimitsu, Rodrigo B. Pimentel, Marcelo Hashimoto, Roberto M. Cesar-Jr., and Roberto Hirata-Jr.In IEEE International Conference on Computer Vision Workshops, 2011We present a mobile device application that uses information from Wi-Fi signals and from the device’s camera to help the localization estimation in indoor environments. The application runs entirely on the mobile device without relying on an external server to achieve real-time performance. The estimation of the localization using camera information is accomplished by keygraph matching between previously selected sign images whose location are known in the environment. The estimation of the Wi-Fi localization is implemented using a naive Bayes classifier on the signals of existing local wireless networks. The final estimation is achieved by using the latter as a rougher estimation of the device location while no sign is detected and, when the device gets closer to a sign, by using the camera to refine the initial Wi-Fi estimation to obtain a much more precise localization. We show results obtained with our approach on a local indoor environment.
@inproceedings{morimitsu2011wifi, author = {Morimitsu, Henrique and Pimentel, Rodrigo B. and Hashimoto, Marcelo and Cesar-Jr., Roberto M. and Hirata-Jr., Roberto}, title = {Wi-fi and Keygraphs for Localization with Cell Phone}, booktitle = {IEEE International Conference on Computer Vision Workshops}, pages = {92--99}, year = {2011}, doi = {10.1109/ICCVW.2011.6130228}, } -
 Keygraphs for Sign Detection in Indoor Environments by Mobile PhonesHenrique Morimitsu, Marcelo Hashimoto, Rodrigo B. Pimentel, Roberto M. Cesar-Jr., and Roberto Hirata-Jr.In Graph-Based Representations in Pattern Recognition, 2011
Keygraphs for Sign Detection in Indoor Environments by Mobile PhonesHenrique Morimitsu, Marcelo Hashimoto, Rodrigo B. Pimentel, Roberto M. Cesar-Jr., and Roberto Hirata-Jr.In Graph-Based Representations in Pattern Recognition, 2011We present an application for mobile phones to detect indoor signs and help in localization. Because it depends only on device capabilities, it is flexible and unconstrained. Detection is accomplished online by keygraph matching between sign images collected offline and the image from a mobile camera phone. After detection we apply a simple localization method based on a comparison between the detected sign and a dataset, consisting of images of the whole environment taken at different positions. We show the results obtained using the application in a local indoor environment.
@inproceedings{morimitsu2011keygraphs, author = {Morimitsu, Henrique and Hashimoto, Marcelo and Pimentel, Rodrigo B. and Cesar-Jr., Roberto M. and Hirata-Jr., Roberto}, title = {Keygraphs for Sign Detection in Indoor Environments by Mobile Phones}, booktitle = {Graph-Based Representations in Pattern Recognition}, series = {Lecture Notes in Computer Science}, editor = {Jiang, Xiaoyi and Ferrer, Miquel and Torsello, Andrea}, publisher = {Springer Berlin / Heidelberg}, pages = {315--324}, volume = {6658}, year = {2011}, doi = {10.1007/978-3-642-20844-7_32} }
2010
-
 Using visual metrics to selecting ICA basis for image compression: a comparative studyPatricia R. Oliveira, Henrique Morimitsu, and Esteban F. TuestaIn Advances in Artificial Intelligence–IBERAMIA 2010, 2010
Using visual metrics to selecting ICA basis for image compression: a comparative studyPatricia R. Oliveira, Henrique Morimitsu, and Esteban F. TuestaIn Advances in Artificial Intelligence–IBERAMIA 2010, 2010In order to obtain a good image compression result, it would be appropriate to previously estimate the error between a distorted image and its reference in such a process. Traditionally, the Mean-Squared Error (MSE) has been used as a standard measure for evaluate the effect of dimensionality reduction methods. More recently, other measures for assessing perceptual image quality has been proposed in the literature. In this paper, the main interest relies on a comparative study between the MSE and the Structural Similarity Index (SSIM), which uses structural similarity as a principle for measuring image quality. The basic aiming for such study is the proposal of an ordering and selecting procedure of the transformation basis found by Independent Component Analysis (ICA), which can take one of these measures into account. The principal motivation for this idea is that, in contrast to Principal Component Analysis (PCA), ICA does not have a property that allows a natural ordering for its components (called ICs). For evaluating the efficiency of such approach, a comparative study between PCA and the ICA-based proposal is also carried out for an image dimensionality reduction application. It can been noted that the ICA method, when using hyperbolic tangent function, could provide an efficient method to select the best ICs.
@inproceedings{oliveira2010using, title = {Using visual metrics to selecting ICA basis for image compression: a comparative study}, author = {Oliveira, Patricia R. and Morimitsu, Henrique and Tuesta, Esteban F.}, booktitle = {Advances in Artificial Intelligence--IBERAMIA 2010}, pages = {80--89}, year = {2010}, publisher = {Springer}, doi = {10.1007/978-3-642-16952-6_9} }